
07. August 2023
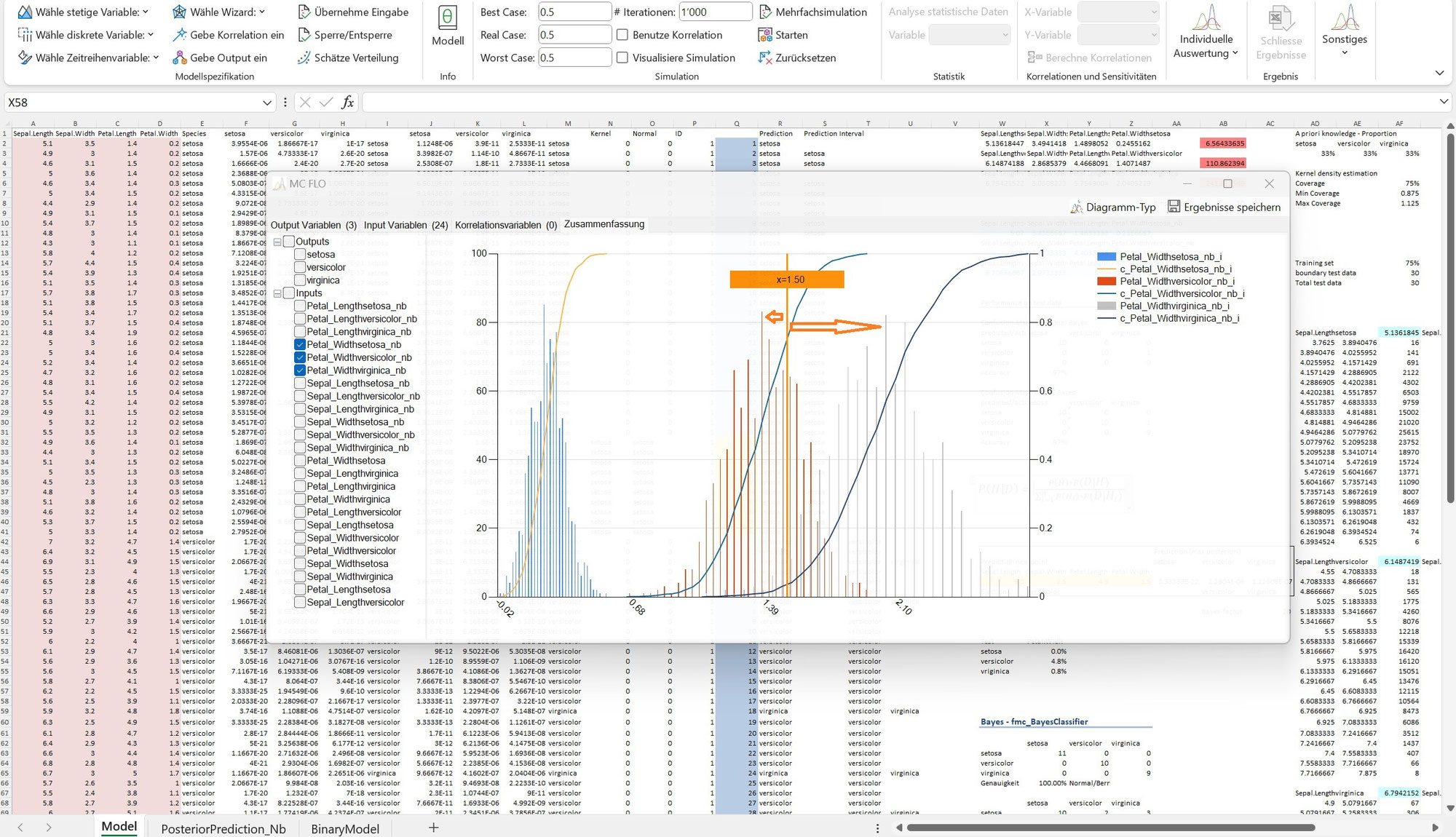
Im Gegensatz zu klassischen Regressionsmodellen, welche Grenzen im Datenraum ziehen und somit zu den diskriminierenden Modellen gezählt werden, verstehen sich generative Modelle – wie der Naive Bayes Klassifikator und ChatGPT – als solche, welche Daten mittels Verteilungen zusammenfassen und somit in der Lage sind neue Daten zu simulieren.

26. Oktober 2020
In einer unserer letzten Blogs haben wir das Data Mining mittels Simulationen und den Vergleich mit einigen der in R implementierten Klassifizierungsalgorithmen kurz vorgestellt. Hier wollen wir den Sachverhalt anhand der in R verfügbaren Testdaten zu Brustkrebserkennung etwas vertiefen und dabei die benutzerdefinierte Verteilung von MC FLO näher vorstellen.